Numerical data
Visualization and summary statistics (part 1)
2025-09-15
Variability
At the heart of statistics is also the variability or spread of the distribution of the variable
We will work with variance and standard deviation, which are ways to describe how spread out data are from their mean
Scatterplots
Scatterplots are bivariate (two-variable) visualizations that provide a case-by-case view of the data for two numerical variables
- Each point represents the observed pair of values of variables 1 and 2 for a case in the dataset
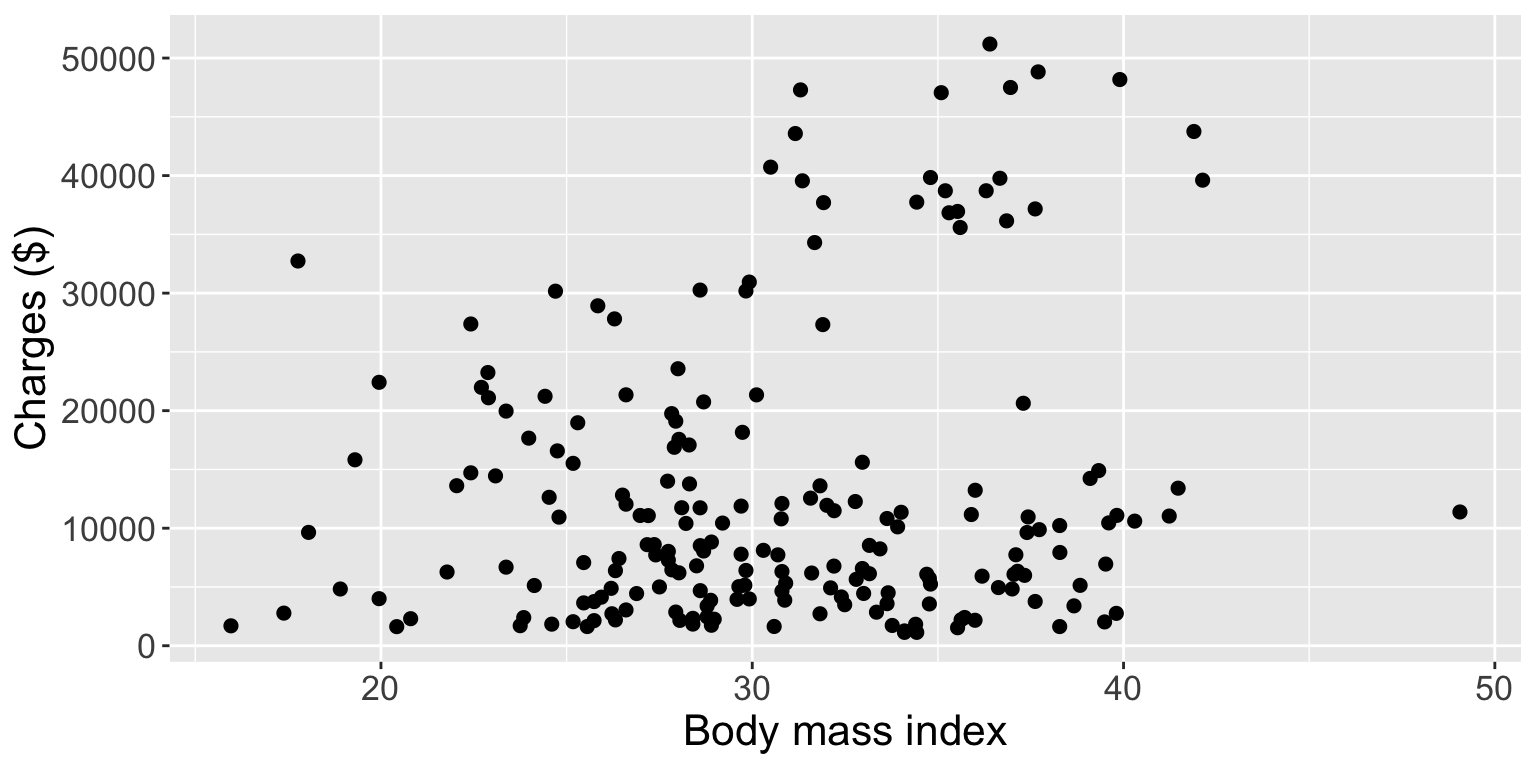
Scatterplots (cont.)
Use scatterplots to reveal:
Association (positive, negative, none), and if there is an association:
The strength (very weak to very strong)
The type of association (e.g. linear, quadratic)
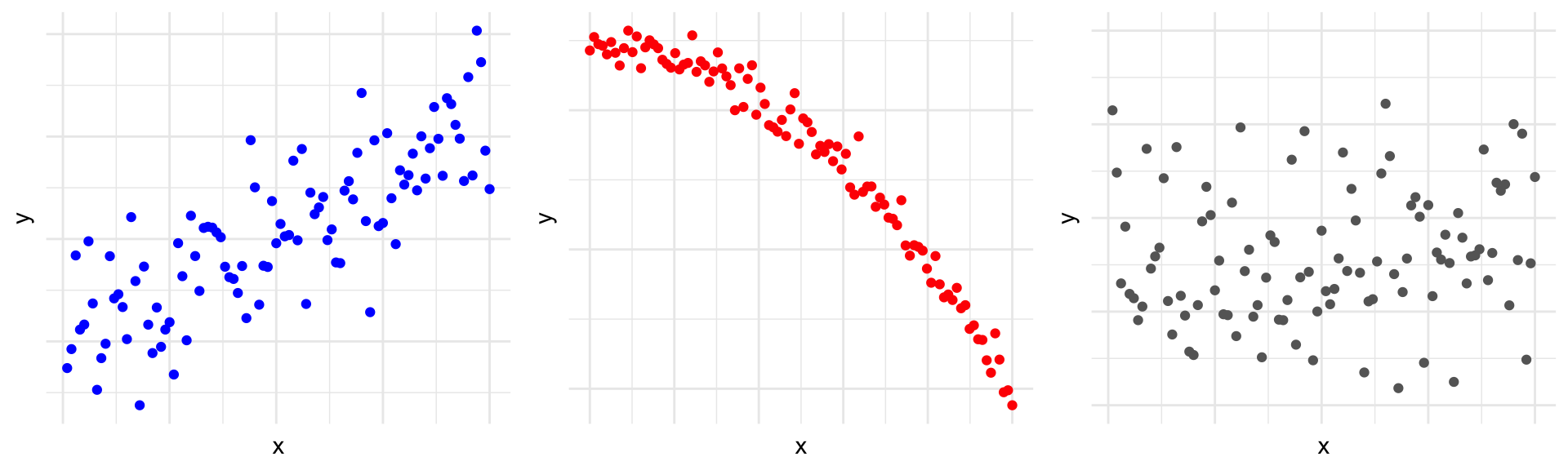
- If there is a notion of explanatory and response, the explanatory goes on \(x\)-axis!
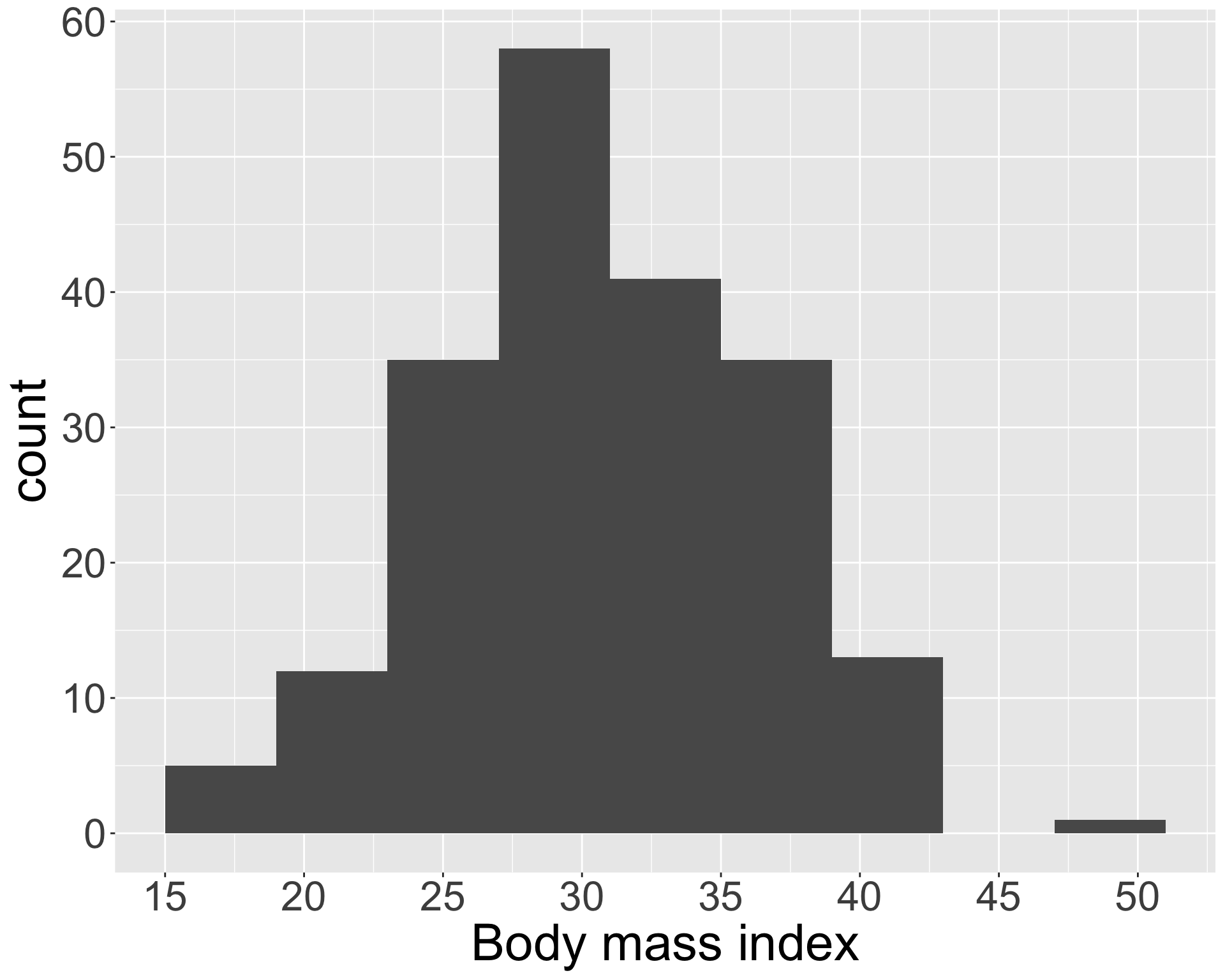
Histograms
Histograms are visualizations that display the binned counts as bars for each bin.
- Histograms provide a view of the density of the data (the values the data take on as well as how often)
| bmi_bin | count |
|---|---|
| [15, 19) | 5 |
| [19, 23) | 12 |
| [23, 27) | 35 |
| [27, 31) | 58 |
| [31, 35) | 41 |
| [35, 39) | 35 |
| [39, 43) | 13 |
| [49, 52) | 1 |
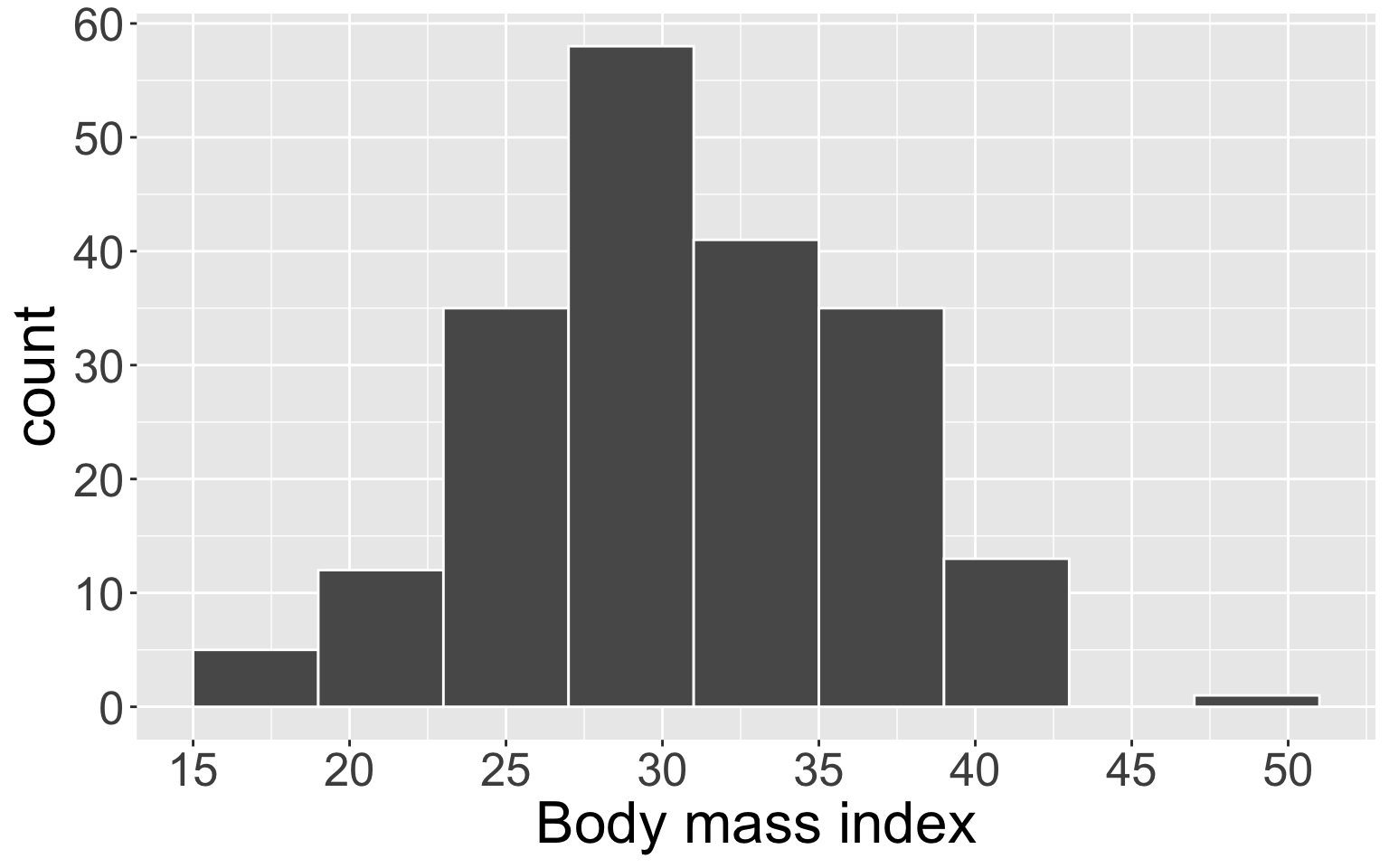
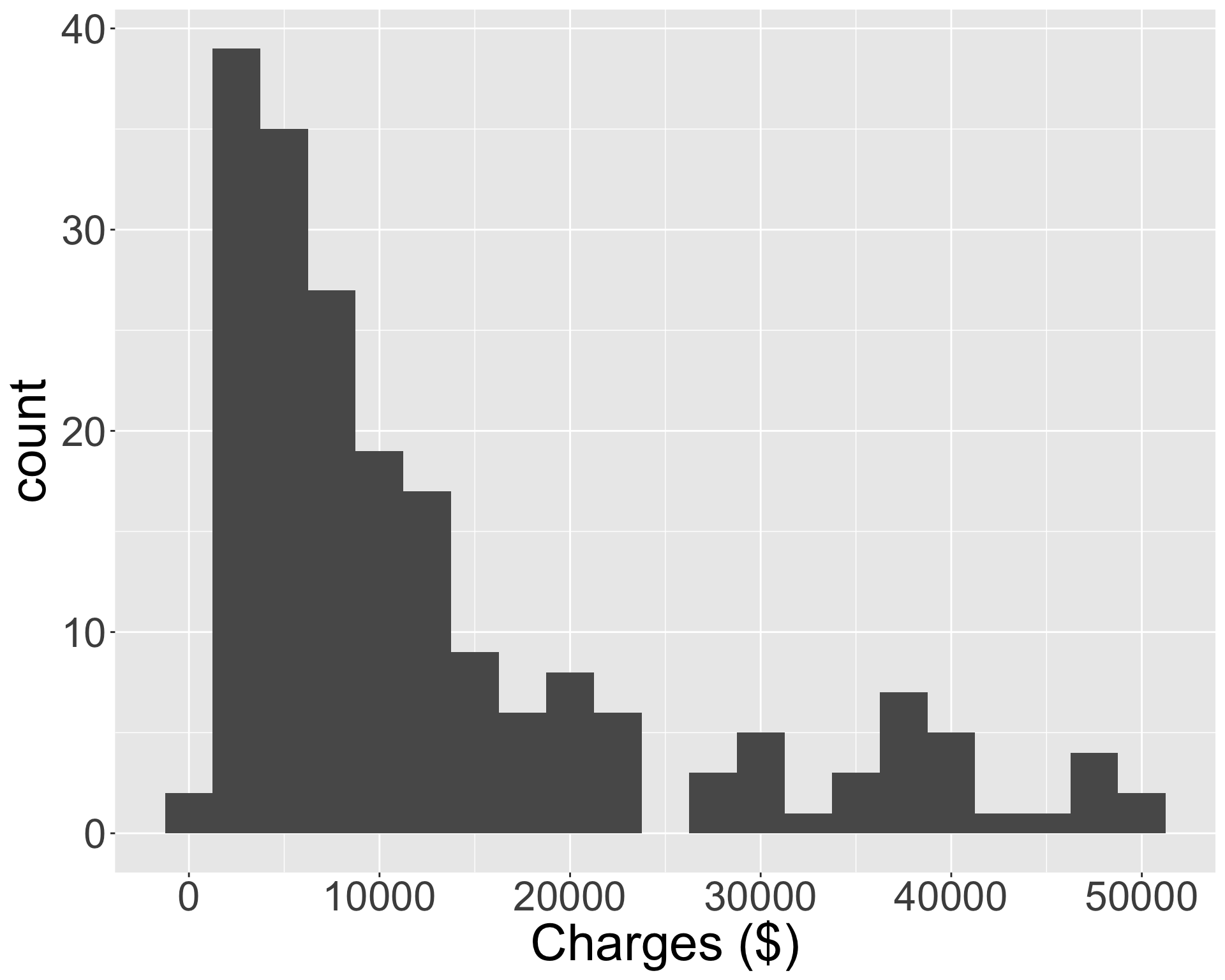
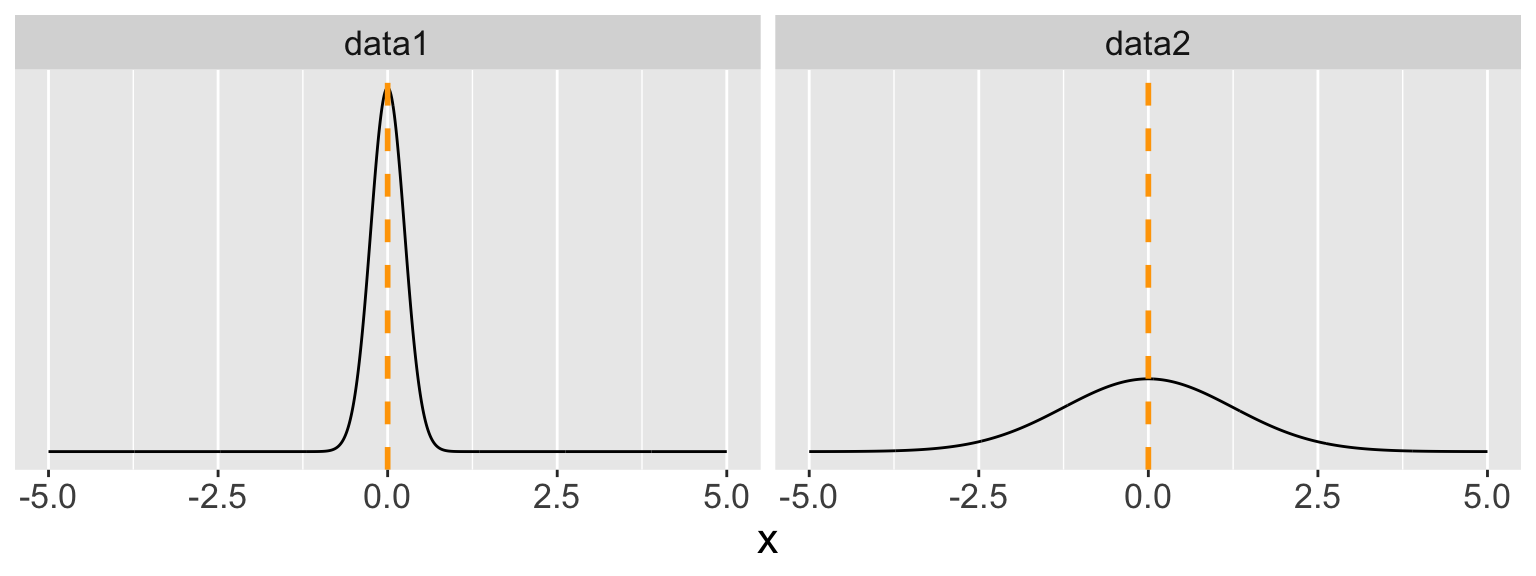
Histograms (cont.)
How would you describe the shape (i.e. skewness and modality) of the distributions in the following two histograms?