Numerical data
Visualization and summary statistics (part 2)
2025-09-17
Visualizing SD
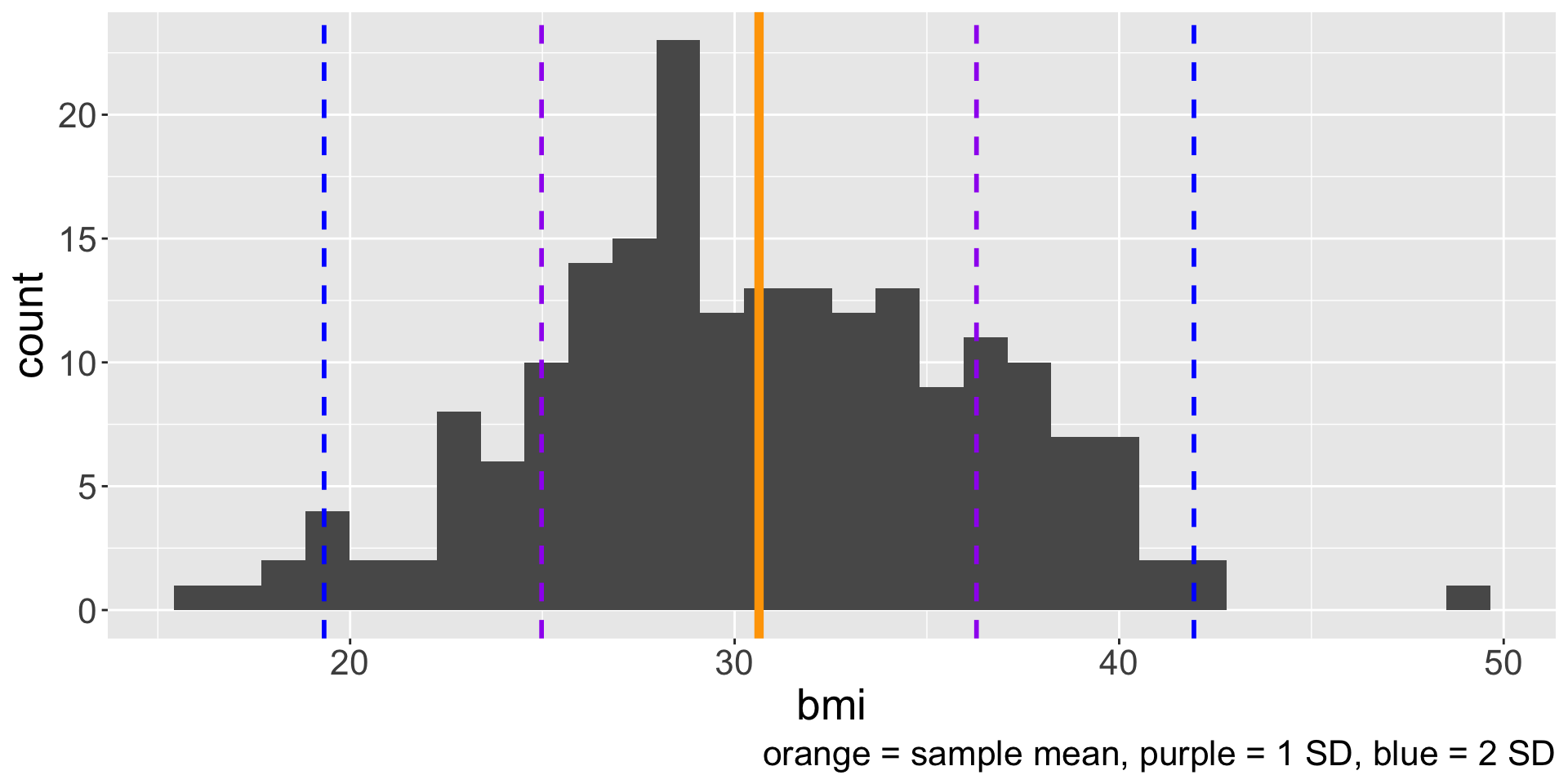
Visualizing SD (cont.)
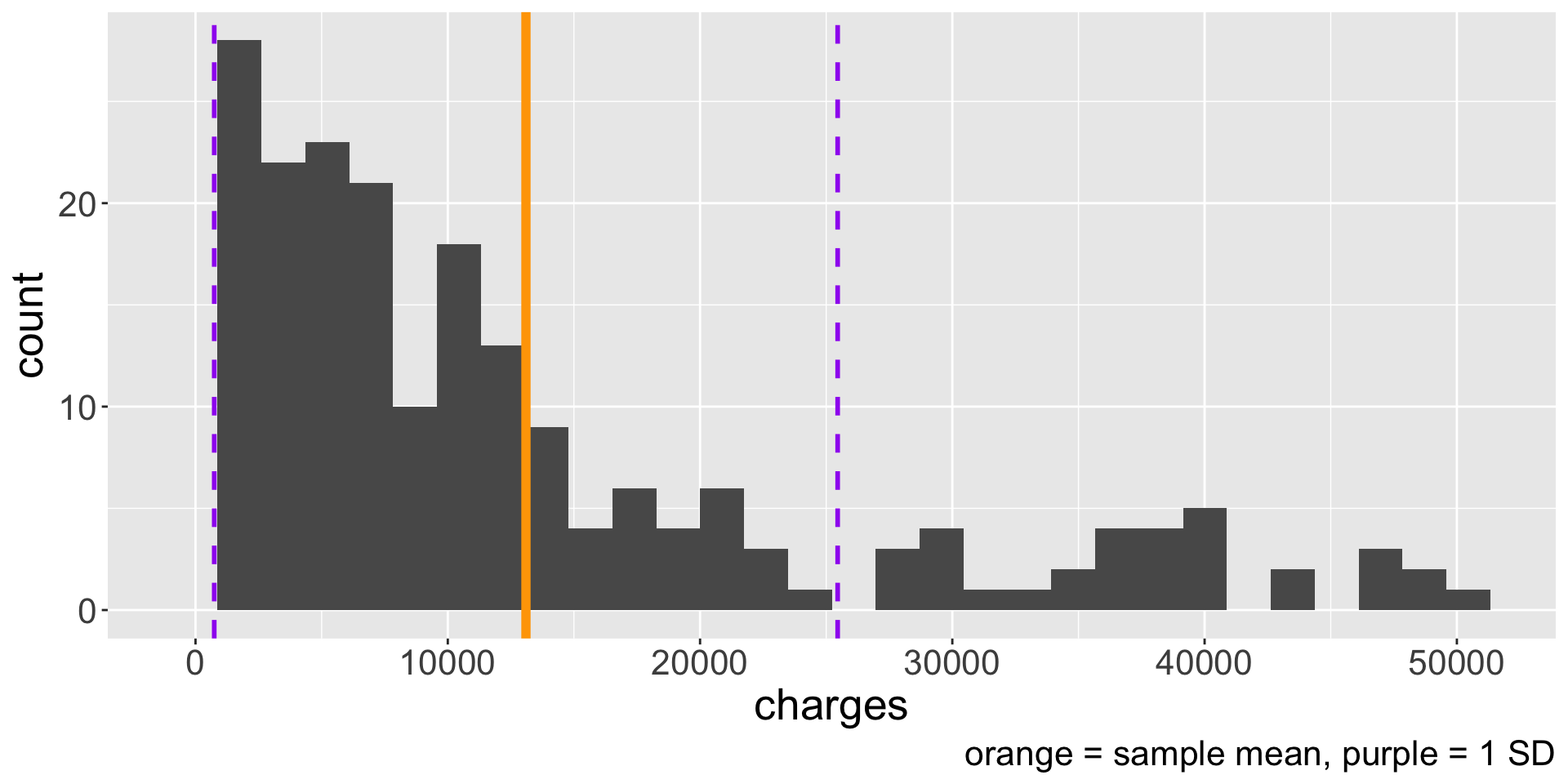
We know how to calculate some summary statistics and interpret them alongside the histogram. But wouldn’t it be great if we had a visualization that directly displays some summary statistics?
Boxplot
Another commonly used visualization to display the distribution of a numerical variable is the boxplot. Boxplots are created using five statistics and identify unusual observations.
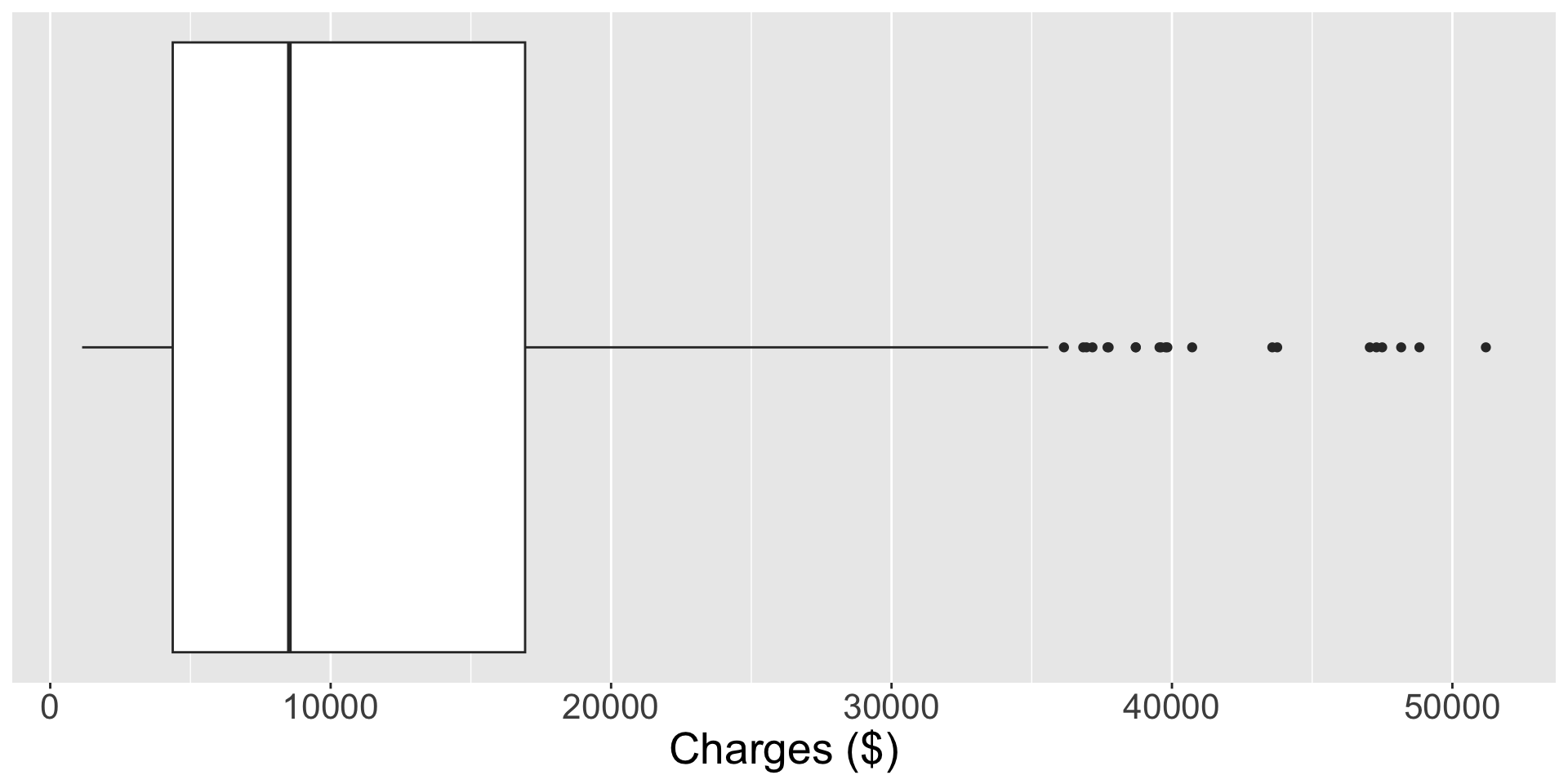
- Does the orientation (vertical or horizontal) matter?
Histograms vs boxplots
What characteristics of the distribution are apparent in the histogram and not in the box plot? What characteristics are apparent in the box plot but not in the histogram?
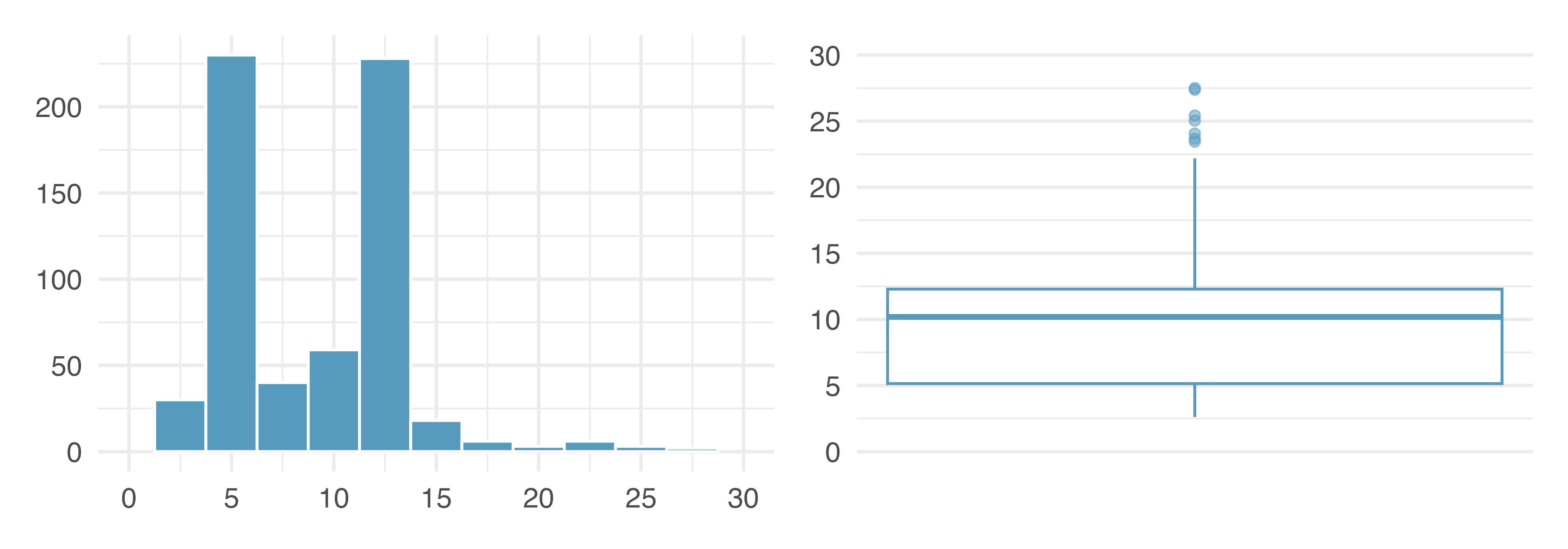
Mean vs. Median
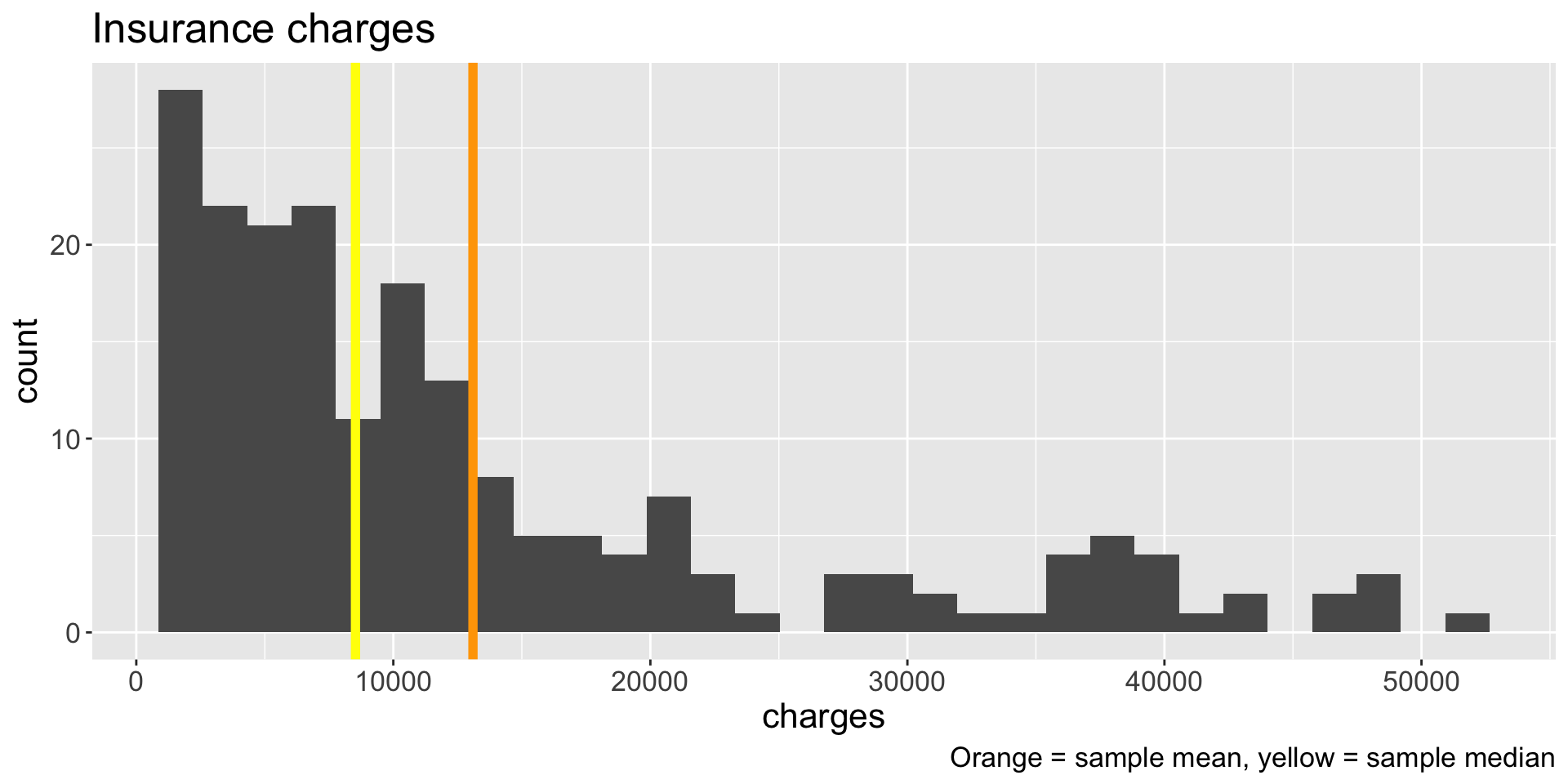
Which is better measure of center? The mean or the median?