CIs and HTs for a single mean
CLT-based
2025-11-03
\(t\)-distribution
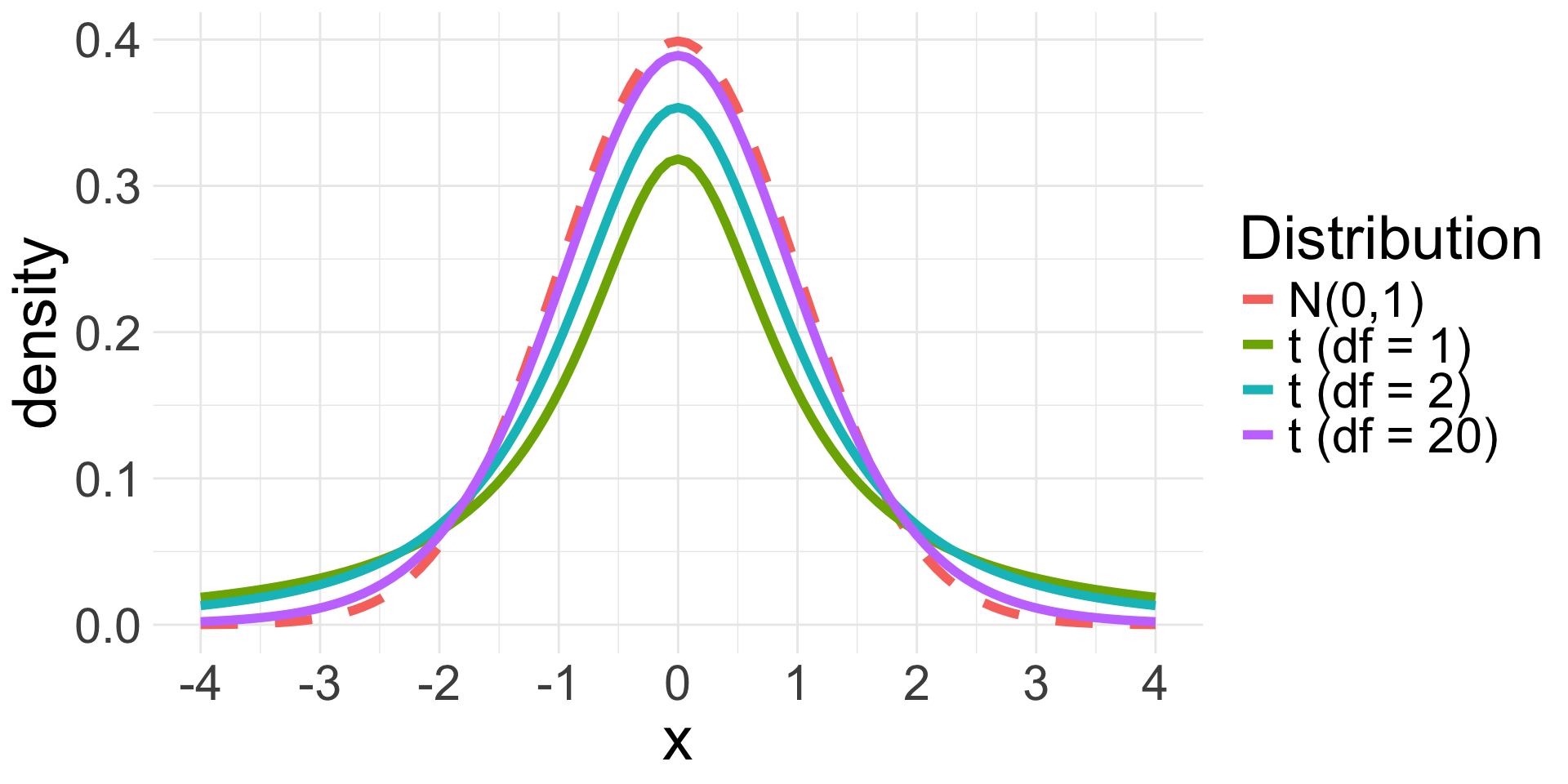
The \(t\)-distribution is symmetric and bell-curved (like the Normal distribution)
Has “thicker tails” than the Normal distribution (the tails decay more slowly)
- \(t\)-distribution is always centered at 0
- One parameter: degrees of freedom (df) defines exact shape of the \(t\)
- Denoted \(t_{df}\) (e.g. \(t_{1}\) or \(t_{20}\))
- As \(df\) increases, \(t\) resembles the \(N(0,1)\). When \(df \geq 30\), the \(t_{df}\) is nearly identical to \(N(0,1)\)
\(t\) distribution in R
pnorm(x, mean, sd)andqnorm(%, mean, sd)used to find probabilities and percentiles for the Normal distributionAnalogous functions for \(t\)-distribution:
pt(x, df)andqt(%, df)
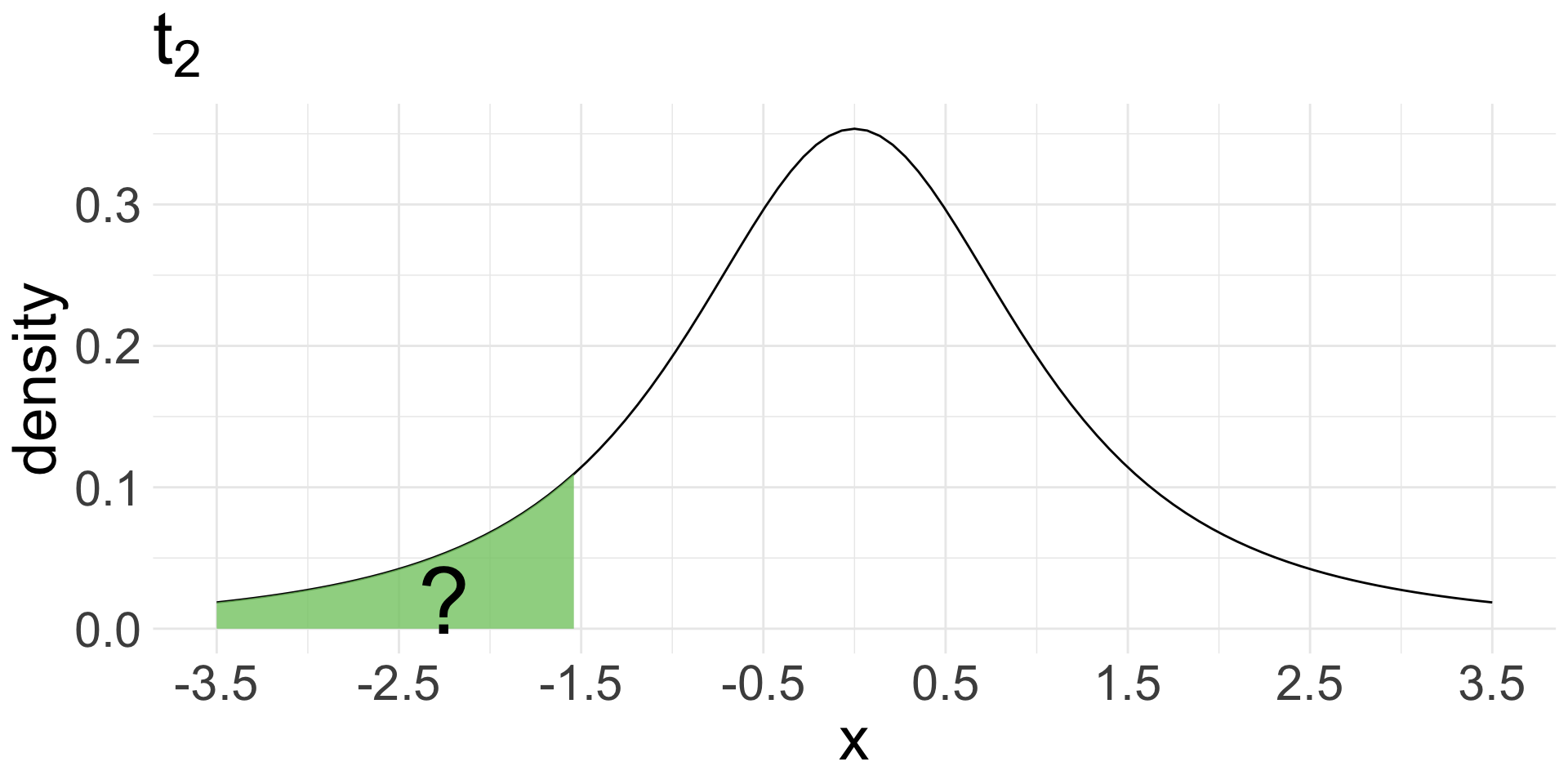
pt(-1.5,df =2) = 0.1361966
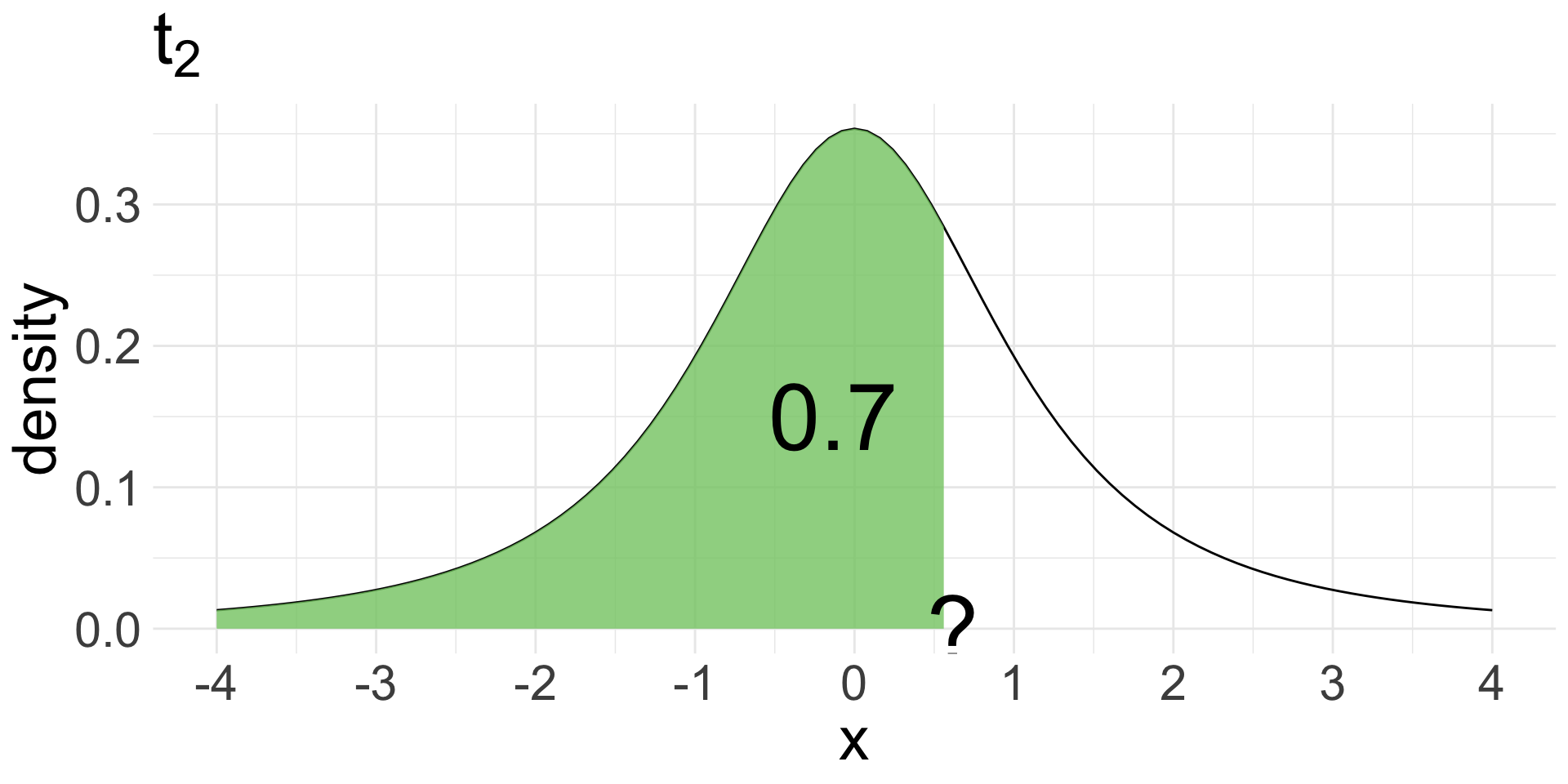
qt(0.7, df =2) = 0.6172134
Example: salinity
The salinity level in a body of water is important for ecosystem function.
We have 30 salinity level measurements (ppt) collected from a random sample of water masses in the Bimini Lagoon, Bahamas.
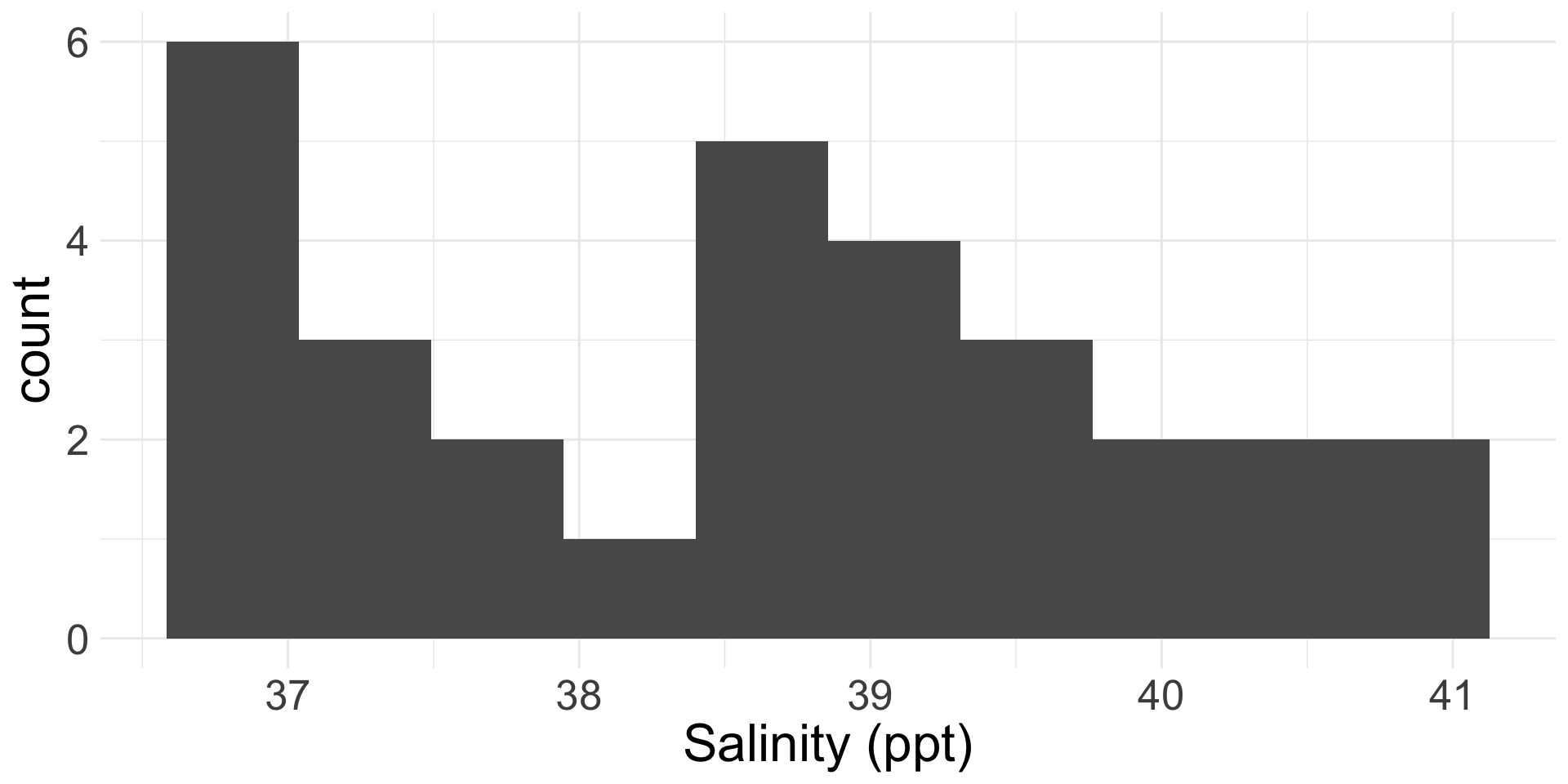
- We want to test if the average salinity level in Bimini Lagoon is different from 38 ppm at the \(\alpha = 0.05\) level.
Example: salinity (cont.)
- Use test-statistic to obtain p-value (draw picture and/or write code using appropriate distribution)